





最近、AI エージェントがコマンドを受け取り、携帯電話上で必要なタップやスワイプなどのタスクを実際に実行するという話題が増えています。 AI エージェントの構築に関するこの話は、2019 年に Pixel 4 とともに発表された「新しい Google アシスタント」をよく思い出させます。
I/O 2019 で、Google はこの次世代アシスタントをデビューさせました。 その仮説は、デバイス上の音声処理によって「携帯電話の電源を入れるためにタップする操作がほとんど遅く感じられる」というものでした。
Googleは、アプリケーションを開いて制御することを含む単純なコマンドを示しましたが、より複雑なアイデアは、「デバイスの内蔵アシスタントがアプリケーション間でタスクをどのように調整できるか」でした。 この例では、受信テキストを受信し、音声で応答し、その後、付随する画像を検索して送信するというアイデアを思いつきました。 「実行」および「マルチタスク」機能は、Gmail の自然言語「作成」機能によって完成されます。
この次世代アシスタントを使用すると、音声で携帯電話を瞬時に操作したり、アプリ間でマルチタスクを実行したり、複雑なアクションを完了したりすることが、すべて実質的にゼロの遅延で可能になります。
新しいアシスタントはその年の後半に Pixel 4 でリリースされ、その後のすべての Google デバイスで利用できるようになりました。
- 「自撮りをしてください。」 次に、「これをライアンと共有してください」と言います。
- 会話スレッドで、「返信してください。向かっています」と言います。
- 「YouTube でヨガのクラスを見つけてください。」 次に、「これをお母さんと共有してください」と言います。
- 「Gmail でミシェルからのメールを見せてください。」
- Google フォト アプリが開いているときに、「ニューヨークの写真を見せて」と言います。 次に、「セントラルパークにあるもの」と言います。
- Chrome でレシピ サイトを開いているときに、「チョコレート ナッツ マフィンを検索して」と言うことができます。
- 旅行アプリが開いているときに、「パリのホテル」と言います。
これが AI エージェントの基本的な考え方です。 先月行われたAlphabetの決算会見で、Sundar Pichai氏はアシスタントに対する生成AIの影響について質問された。 同氏は、これによりGoogleアシスタントが「時間の経過とともにプロキシとして機能」し、「答えを超えてユーザーを追跡」できるようになるだろうと述べた。
によると 情報 今週、OpenAI は ChatGPT プロキシに取り組んでいます。
「この取り組みに詳しい関係者によると、こうした種類のリクエストは、クリック、カーソルの移動、テキスト入力、その他人間がさまざまなアプリケーションを操作するときに行うアクションをエージェントに促すことになる。」
次に、既存のモバイルおよびデスクトップ インターフェイスと対話して特定のタスクを完了するようにトレーニングされた Large Action Model (LAM) Rabbit があります。
2019年にGoogleアシスタントによって導入されたバージョンは、非常に事前にプログラムされているようで、ユーザーが自然に話してからそのアクションを自動的に強調表示するのではなく、特定のフレーズをコミットする必要がありました。 当時Googleは、アシスタントが「多くのアプリとシームレスに連携」し、「今後もアプリの統合を改善し続ける」と述べた。 私たちの知る限り、このようなことは一度も起こったことはありませんが、Google が実証した機能の一部は、アプリケーションの変更により動作しなくなりました。 真のエージェントは、設定された条件に依存するのではなく、適応することができます。
昨年 Google Research が「大規模な言語モデルを使用してモバイル UI との会話型対話を可能にする」。

Google の調査によると、彼らのアプローチは「モバイル UI の意図を迅速に理解」できることがわかっています。
興味深いことに、LLM の学生は概要を作成する際に、事前の知識を利用して、ユーザー インターフェイスに表示されていない情報を推測していることが観察されました。 以下の例では、LLM は地下鉄の駅がロンドンの地下鉄システムに属していると推測していますが、入力 UI にはこの情報が含まれていません。
また、ユーザー インターフェイスに表示されるコンテンツに関する質問に答え、自然言語の指示を受け取った後に制御することもできます。
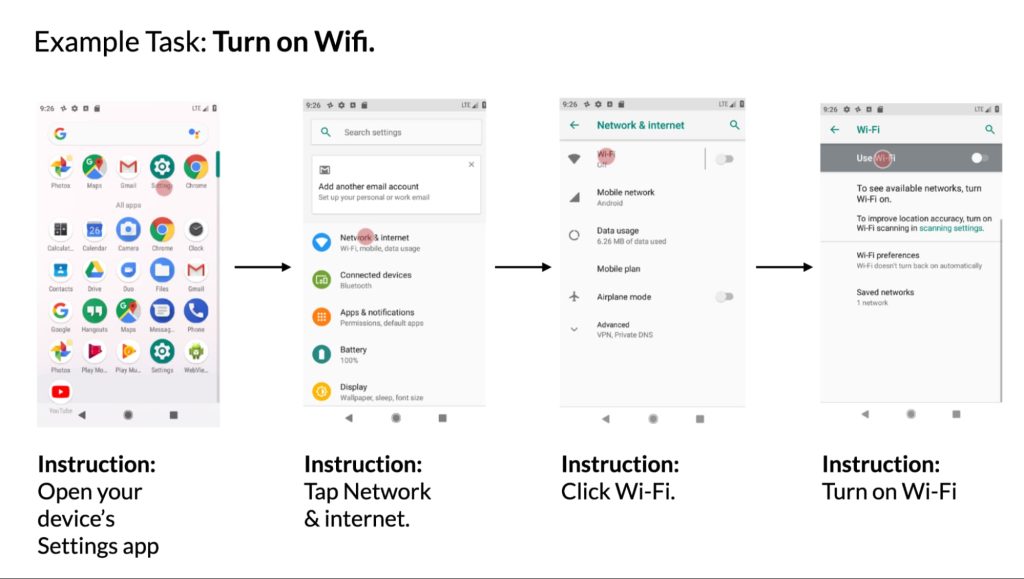
Android デバイス用の Gemini AI エージェントは、携帯電話の新しい使用方法を提供するオールインワン アシスタントに対する Google の最初の、これまでに発見されたことのない試みの自然な進化です。 ただし、メッセージへの返信をコピーして、Gboard アシスタントの音声入力で直接「送信」と言える機能もあります。
これまでの取り組みは、Googleがアイデアを出すのが遅れ、必要な技術を持っていなかったことが原因とみられる。 ここまで来たら、Google はこの取り組みを優先して、追いつくのではなく、この分野をリードできるようにするのが賢明でしょう。
FTC: 私たちは収入を得るために自動アフィリエイト リンクを使用しています。 もっと。

“Analyst. Television trailblazer. Bacon fanatic. Internet fanatic. Lifetime beer expert. Web enthusiast. Twitter fanatic.”
More Stories
iPhone 17の噂:新デザイン、「Plus, more」に代わる「スリム」モデル。
米国のトップがんセンターMDアンダーソンがいじめスキャンダルに巻き込まれ、トップ医師が「マフィア流虐待」と盗作で告発される
Valve が 100 時間を超えたプレイヤーに払い戻しを行う方針を無視したため、Helldivers 2 は PSN にアクセスできない状態で 170 か国の Steam から削除されました